
하이퍼파라미터 튜닝 방법 중 하나인 Optuna에 대해 소개하고자 합니다. Optuna에 대한 설명 및 기존의 GridSearchCV, RandomSearchCV와 어떤점이 다른지 알아보겠습니다.
1. Optuna란 무엇인가?
Optuna는 기계 학습 모델의 하이퍼파라미터를 자동으로 조정하고 최적화하는 오픈 소스 라이브러리입니다. 2019년에 처음 공개되어, 기계 학습 모델의 성능을 개선할 수 있는 가장 좋은 하이퍼파라미터를 찾는 데 도움을 줍니다. Optuna는 Python으로 작성되었으며, 사용자 친화적인 API를 제공합니다. 이를 통해 사용자는 복잡한 코드 변경 없이도 다양한 하이퍼파라미터의 효율적인 탐색이 가능해집니다. Optuna는 딥러닝뿐만 아니라, 다양한 유형의 기계 학습 알고리즘에서 널리 사용될 수 있습니다.
2. Optuna 메커니즘
Optuna의 핵심 기능은 "효율적인 하이퍼파라미터 최적화"에 있습니다.
최적화 과정은 크게 두 가지 주요 메커니즘으로 이루어집니다
- 트리 기반의 구조화된 파라미터 최적화 (TPE)
- 프루닝 메커니즘
트리 기반의 구조화된 파라미터 최적화 (TPE)
TPE는 베이지안 최적화의 일종으로, 이전의 평가 결과를 기반으로 하여 하이퍼파라미터의 새로운 셋을 제안합니다. 기존의 랜덤 혹은 격자(grid) 검색 방법보다 효율적으로 공간을 탐색합니다. TPE는 모델의 성능을 가장 잘 향상시킬 것으로 예상되는 하이퍼파라미터의 조합에 더 많은 자원을 할당합니다.
프루닝 메커니즘
프루닝은 계산 자원의 낭비를 줄이기 위해 비효율적인 트라이얼(시도)을 조기에 중단시키는 기술입니다.
예를 들어, 특정 하이퍼파라미터 셋으로 훈련 중인 모델이 중간 평가에서 기대치에 미치지 못할 경우, 추가적인 훈련 없이 해당 트라이얼을 중단시킵니다. 이는 전체 최적화 프로세스의 속도를 높이고, 불필요한 계산 자원의 소모를 방지합니다.
이러한 메커니즘을 통해 Optuna는 하이퍼파라미터 최적화 과정에서 시간과 자원을 효율적으로 사용하면서도, 모델의 성능을 극대화할 수 있는 최적의 조합을 찾아낼 수 있습니다. 사용자는 목적 함수를 정의하기만 하면, Optuna가 자동으로 최적의 하이퍼파라미터를 탐색하고 평가합니다.
3. Optuna의 주요 장점 (위에 내용 정리)
- 효율적인 검색 알고리즘
- TPE(트리 기반의 구조화된 파라미터 최적화) 알고리즘은 전통적인 격자(grid) 검색이나 랜덤 검색에 비해 더 효율적으로 하이퍼파라미터 공간을 탐색합니다. 이는 더 적은 시도로 더 좋은 결과를 얻을 수 있음을 의미합니다.
- 자동 프루닝 기능
- 비효율적인 트라이얼을 조기에 중단시킬 수 있는 자동 프루닝 기능을 제공합니다. 이를 통해 불필요한 계산 자원의 낭비를 줄이고, 전체 최적화 과정의 속도를 높일 수 있습니다.
- 병렬화 용이
- 분산 환경에서의 병렬 실행을 쉽게 지원합니다. 대규모 실험을 빠르게 처리할 수 있게 하여, 큰 데이터 세트나 복잡한 모델에서 매우 유용합니다.
- 사용자 정의 가능한 최적화
- 사용자는 자신의 목적 함수를 자유롭게 정의할 수 있으며, Optuna는 이를 기반으로 최적화를 수행합니다. 다양한 유형의 문제에 유연하게 적용될 수 있는 맞춤형 최적화를 가능하게 합니다.
- 시각화
- 최적화 과정을 분석하고 이해하는 데 도움이 되는 다양한 시각화 도구를 제공합니다. 시각화를 통해 사용자는 하이퍼파라미터의 영향을 보다 명확하게 파악하고, 더 나은 결정을 내릴 수 있습니다.
4. GridSearchCV, RandomSearchCV, Optuna : 비교 표
| 특성/도구 | GridSearchCV | RandomSearchCV | Optuna |
| 검색 방식 | 격자 검색 | 랜덤 검색 | 트리 기반의 구조화된 파라미터 최적화 |
| 최적화 속도 | 느림 | 중간 | 빠름 |
| 자원 활용 효율 | 낮음 | 중간 | 높음 |
| 프루닝 기능 | 없음 | 없음 | 있음 |
| 사용자 정의 최적화 | 제한적 | 유연함 | 매우 유연함 |
| 시각화 도구 | 기본적인 시각화 지원 | 기본적인 시각화 지원 | 시각화 도구 제공 |
5. Optun 코드 및 사용
5.1 Optuna 설치
!pip install optuna
!pip install -U -qqq hiplot # 시각화5.2. 예시 - 여러 개의 모델 중 성능이 가장 좋은 모델 및 하이퍼파라미터 튜닝
예시로 제가 사용하고자 하는 모델 3개를 가지고 와서 제일 값이 좋은 모델의 하이퍼파라미터 값을 튜닝하려고 합니다. 이럴 경우, 하나씩 모델을 사용하는 것보다 여러 개를 한 번에 비교하면서 최적의 값을 찾을 수 있어 시간단축이 될 수 있습니다.
import optuna
# Optuna를 위한 목적 함수 정의
def objective(trial):
model_name = trial.suggest_categorical('model', ['XGBoost', 'LightGBM', 'CatBoost'])
if model_name == 'XGBoost':
params = {
'subsample': trial.suggest_float('subsample', 0.7, 0.8),
'n_estimators': trial.suggest_int('n_estimators', 100, 150),
'min_child_weight': trial.suggest_int('min_child_weight', 6, 8),
'max_depth': trial.suggest_int('max_depth', 8, 10),
'learning_rate': trial.suggest_float('learning_rate', 0.1, 0.15),
'gamma': trial.suggest_float('gamma', 0.1, 0.2),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.3, 0.5),
'random_state': 42
}
model = xgb.XGBRegressor(**params)
elif model_name == 'LightGBM':
params = {
'num_leaves': trial.suggest_int('num_leaves', 20, 40),
'n_estimators': trial.suggest_int('n_estimators', 100, 200),
'min_child_weight': trial.suggest_int('min_child_weight', 5, 20),
'max_depth': trial.suggest_int('max_depth', 10, 30),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.2),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.4, 0.8),
'random_state': 42,
'force_row_wise': True,
'verbose': -1
}
model = LGBMRegressor(**params)
elif model_name.startswith('CatBoost'):
params = {
'iterations': trial.suggest_int('iterations', 150, 200),
'learning_rate': trial.suggest_float('learning_rate', 0.05, 0.15),
'depth': trial.suggest_int('depth', 6, 8),
'l2_leaf_reg': trial.suggest_int('l2_leaf_reg', 8, 9),
'border_count': trial.suggest_int('border_count', 32, 255),
'random_state': 42,
'verbose': False
}
model = CatBoostRegressor(**params)
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
return rmse(y_val, y_pred)
# Optuna 스터디 생성 및 최적화 실행
# minimize(최소 값) 모델 평가 방법에 따라 변경 maximizer(최대 값)
study = optuna.create_study(direction='minimize')
# 시도 횟수 n_trials = 50번
study.optimize(objective, n_trials=50)
print(f"모델 이름: 최적의 값 = {study.best_value}, 최적의 파라미터 = {study.best_params}")
# 최적의 파라미터와 그때의 RMSE 출력
print("Best trial:")
trial = study.best_trial
print("Value: ", trial.value)
print("Params: ")
for key, value in trial.params.items():
print(f"{key}: {value}")- 모델 평가 방법에 따라 minimize인지 maximizer인지 수정해줘야 합니다.
- 몇 번을 시도할지 횟수도 정해줘야 합니다. (e.g. 시도 횟수 n_trials = 50)
5.3 Optuna 하이퍼파라미터 값 결과

5.4 예시 2 - 단일 모델 하이퍼파라미터 튜닝
단일 모델로 하나의 모델만 돌려봅니다. 혹은 위에 여러 가지 모델을 가지고 하셨다면, 가장 성능이 좋은 모델을 가지고 와서 다시 최적의 값을 찾아봅니다. 예시로 LightGBM으로 해보겠습니다.
import optuna
# LightGBM을 위한 목적 함수 정의
def objective(trial):
params = {
'num_leaves': trial.suggest_int('num_leaves', 20, 40),
'n_estimators': trial.suggest_int('n_estimators', 100, 200),
'min_child_weight': trial.suggest_int('min_child_weight', 5, 20),
'max_depth': trial.suggest_int('max_depth', 10, 30),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.1),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.4, 0.8),
'random_state': 42,
'force_row_wise': True,
'verbose': -1
}
model = LGBMRegressor(**params)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)],)
y_pred = model.predict(X_val)
return rmse(y_val, y_pred)
# Optuna 스터디 생성 및 최적화 실행
# minimize(최소 값) 모델 평가 방법에 따라 변경 maximizer(최대 값)
study = optuna.create_study(direction='minimize')
# 시도 횟수 n_trials = 50번
study.optimize(objective, n_trials=50)
print(f"모델 이름: 최적의 값 = {study.best_value}, 최적의 파라미터 = {study.best_params}")
# 최적의 파라미터와 RMSE 출력
print("Best trial:")
trial = study.best_trial
print("Value: ", trial.value)
print("Params: ")
for key, value in trial.params.items():
print(f"{key}: {value}")5.5 Optuna 하이퍼파라미터 값 결과 (단일 모델)

6. 시각화
다음 코드를 통해 몇 번째에서 나의 하이퍼 파라미터 값이 최저였는지, 최대였는지 확인하실 수 있습니다. 또한 여러 모델을 돌렸을 때 어떤 모델인지, 어떤 값인지 오름차순, 내림차순으로 보실 수 있습니다. 필요하신 분은 사용해 주시면 됩니다.
# Optuna 시각화
from optuna.visualization import plot_optimization_history, plot_param_importances
# 최적화 과정 시각화
plot_optimization_history(study)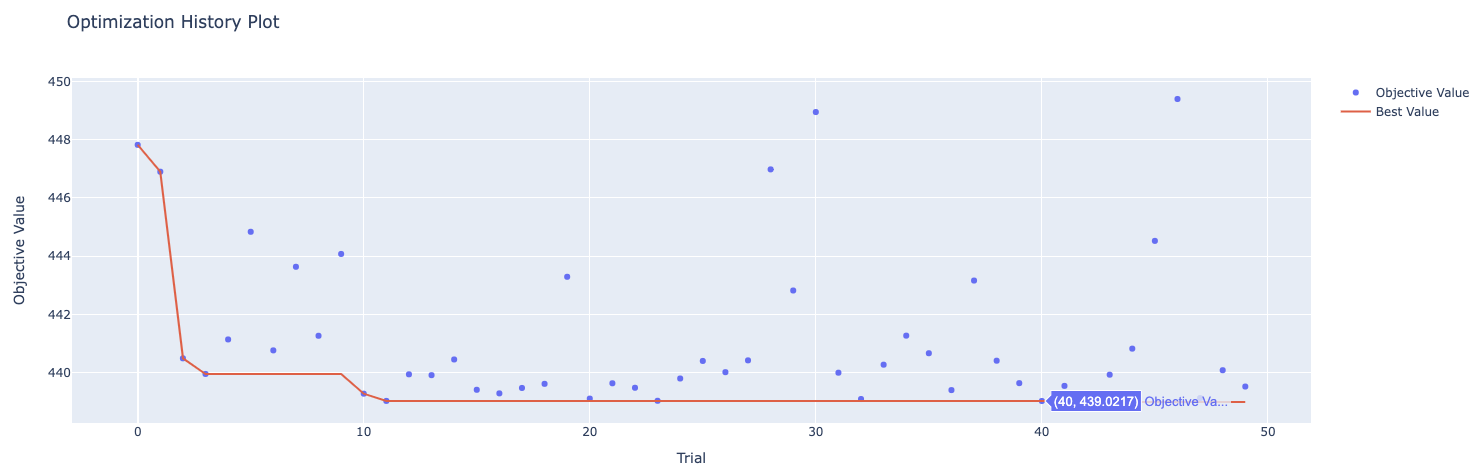
이건 여러 개의 모델을 돌렸을 때 어떤 값이 최저, 최대인지 엑셀처럼 내림차순, 오름차순으로 보실 수 있습니다.
import hiplot as hip
# Optuna 스터디 결과를 hiplot으로 변환
data = [dict(trial.params, value=trial.value) for trial in study.trials]
hip.Experiment.from_iterable(data).display()
7. 결론
GridSearchCV, RandomSearchCV, Optuna 모두 사용해 봤는데, 개인적으로는 시간이 오래 걸리는 GridSearchCV, RandomSearchCV 대신에 굉장히 빨리 찾아주는 Optuna를 자주 사용합니다. 하이퍼파라미터튜닝 방법에는 모두 장단점이 있지만, 자신에게 맞거나 모델에 맞는 최적화 방법을 선택하셔서 사용하시면 됩니다.
안 써보신 분들은 Optuna를 사용하는 것도 하나의 방법이 될 수 있으니 사용해 보시면 좋을 것 같습니다.
공식홈페이지와 Github에 자세하게 적혀있으니 해당링크도 남겨두겠습니다. (참고로 대시보드 관련해서도 자세하게 적혀 있으니 공식 홈페이지를 참고해보세요. )
Optuna 공식홈페이지 : 홈페이지 바로가기
Optuna Github : Github 바로가기
[GridSearchCV 란?]
[머신러닝] GridSearchCV 사용방법(예시)
GridSearchCV 안녕하세요. 이번에 GridSearchCV라는 모듈에 대한 설명과 사용 방법에 대해 예시로 보여주고자 합니다. GridSearchCV란 머신러닝에서 모델의 성능향상(고도화)을 위해 쓰이는 기법 중 하나입
hyunicecream.tistory.com
[RandomSearchCV 란?]
[머신러닝] RandomSearchCV 사용 방법 및 GridSearchCV 차이점
머신러닝 모델의 성능을 높이기 위해 여러 가지 방법을 고안하거나 실행해 보실 텐데, 이번에 HyperParmeter Tuning 방법 중 하나인 RandomSearchCV에 대한 설명 및 사용방법에 알아보고자 합니다. 추가로
hyunicecream.tistory.com